

Lesson #81 - Encoding Relationships between Words
Kris Durski

We are so grateful for your loyalty and support. You are the reason we do what we do. Thank you for being part of our amazing community. You rock! 👏🤟
Recurrent neural networks with LSTM (Long Short-Term Memory) or GRU (Gated Recurrent Unit) elements perform sequential processing of streams of words retaining some context for those words and thus can learn what is coming next. We could see in the previous article that Transformer networks can process words in parallel, which increases the speed of their responses, but independent processing of words loses context provided by the sequence of those words. To allow Transformer networks to process words in a specific context the word embedding has to be enriched in the relationship between words in a sequence. In decoder-only Transformers, this process is called masked self-attention.
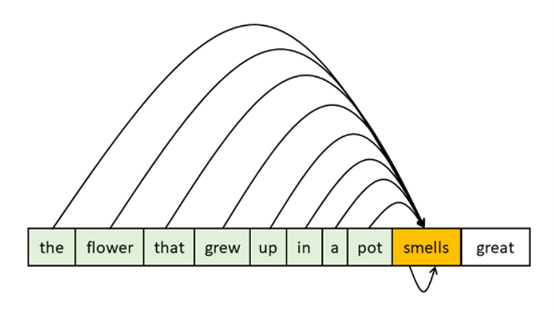
Let’s consider a sequence of words “The flower that grew up in a pot smells great” as shown in Figure 1. Masked self-attention. To provide context information for the word “smells” all words that come before it and the word itself are used.
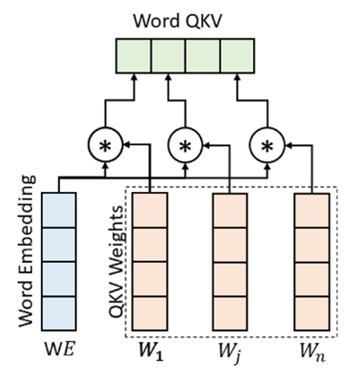
To compute the self-attention there are three matrices of weights Q (Query), K (Key), and V (Value), which are obtained during the training process and are shown in Figure 2. Computing query (Q), key (K), and value (V). The resulting vector Word QKV represents the similarity (dot product) between the Word Embedding WE vector and each column of a relevant weight matrix Q, K, or V. The resulting vector is called Query, Key, or Value depending on the weight matrix used.
Let’s look at computing the masked self-attention of the word “smells” as shown in Figure 3. Computing masked self-attention. For this step we need the Key and Value vectors for all words that precede the word “smells” and for the word of attention all three vectors Query, Key, and Value. We use the Query vector of the word of attention and compute similarity (dot product) to all mentioned Key vectors. The similarity values are fed to the Softmax function, which keeps the same value order, but converts those values to the range 0…1 in such a way that the sum of all values equals 1. So the outputs of the Softmax function can be interpreted as fractions of Value vectors of each considered word that contribute to the attention of a word of interest and in this case, the word “smells”.
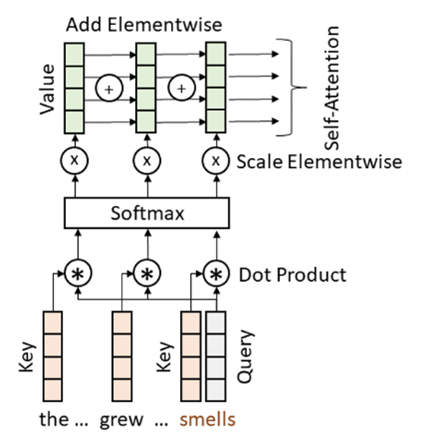
The training of weights should resolve the issue that the word “smells” should have more similarity to the more distant word “flower” than the word “pot”, which is a direct neighbor to the word of interest. The masked self-attention is also a vector of the same size as word embedding and is added to the word embedding vector before it is fed to the fully connected neural network.
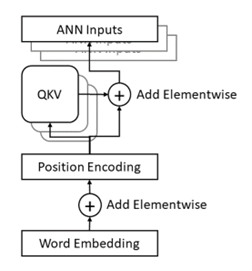
The module that performs full preprocessing of each word can be summarized as shown in Figure 4. Word preprocessing. The QKV module is often called an Attention Head and uses the same weights for each word. To improve the resolution of concepts in the parameter space of a neural network there could be multiple Attention Heads per word, each using different sets of trainable weights.
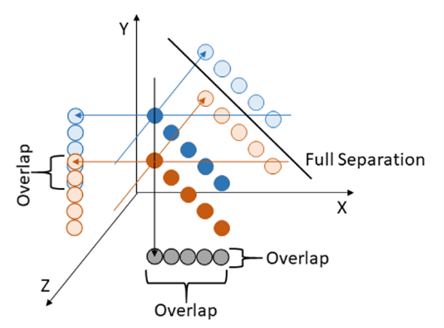
To see how dimensionality can resolve the overlap of classes of concepts in the parameter space let’s look at Figure 5. Dimensionality and resolution of overlapping classes. The two sets of points fully overlap each other in the plane X and Z, partially overlap in the plane Y and Z, but are fully resolved in the plane X and Y. It is visible that by adding one dimension we can significantly improve the dichotomy of two classes of points. In practice, the dimensionality has to be a balance between the speed of processing, the ability to distinguish different classes, and the overfitting of training samples.
Before we finish this part we have to introduce one more token that tells the Transformer to start generating output based on the received input sequence called prompt. The token is called the end of sequence or EOS. Once the network receives the EOS token it starts generating output words until it generates another EOS token. The Transformer network predicts the next word in a sequence while processing the input words and then after the EOS token is received it predicts output word after word extending the prompt with predicted words so the processing continues the same way. First, each predicted word is position encoded, then the masked self-attention is computed and added and finally fed to the fully connected neural network.
It is easy to guess that computing masked self-attention of long sequences even if a prompt is short but the output sequence is long could be very challenging especially when targeting a personal language model that runs on edge devices with limited computing power. Unlike the computations for the prompt words which can mostly be done in parallel, the output words can only be computed in sequence once a word is predicted. There is some parallelism in the processing of an output word, but overall it goes word by word. Ways to mitigate this problem which is a bottleneck of scalability are being continuously researched. A thorough explanation of this process will be presented in the next article of this series.
Thank you for reading our newsletter and stay tuned for more updates from Vault Security!

It’s been a pleasure to share this article with you today. I hope you found it informative and interesting. I’ll be back next Sunday with more insights and stories. Until then, I wish you a great day and all the best.👋.